生成AIを使っていて、「毎回同じ指示を繰り返す」「回答に前の情報が混ざる」といった経験はありませんか?これは、AIが抱える「長期記憶の欠如」や「情報の混濁」が原因です。
もし、AIが人間のような記憶能力を持てば、よりチャットのやり取りがスムーズになり、業務効率は大きく向上するでしょう。実は、その未来はもう目前まで迫っています。
本記事では、長期記憶を実現する新フレームワーク「MIRAS」を、Googleの論文をもとにわかりやすく解説します。同時に発表された「Titans」との関係もお伝えするので、ぜひこの機会に最新AIの画期的技術をご確認ください。
Googleの「MIRAS」とは?

GoogleのMIRAS(ミラーズ)とは、現代のAIがどのように情報を記憶し、活用するかを統一的に説明したフレームワーク(設計理論)です。
2025年12月4日、Google ResearchはこのMIRASと、それを具体化した新構造・Titans(タイタンズ)の論文を発表しました。
『It’s All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization』
(すべてはつながっている:テスト時記憶、アテンショナルバイアス、保持、オンライン最適化をめぐる旅)
AIの記憶を決定づける4つの動作
AIが情報を記憶する行為は、次の4つの動作の組み合わせで成り立っています。
- 何を蓄えるか(記憶構造)
- どれを優先するか(重要度の判断)
- どれだけ残すか(保持・忘却)
- どう更新するか(学習の仕方)
これは、Google Researchの論文がMIRASの4つの選択肢として定義している内容そのものです。この4つをどのように組み合わせるかによって、モデルの性質、つまりAIの記憶の特性が決まります。
MIRASは共通の設計理論
MIRASは、個別の技術ではなく共通の設計理論を示したフレームワークです。これは、自動車に例えるとわかりやすくなります。
- セダン、SUV、ミニバンなど車の形はそれぞれ違う
- しかし、どの車も4つの車輪で動き、アクセルで加速しブレーキで止まる
- つまり、見た目が異なっても基本構造は一緒
MIRASの考え方もこれと同じで、これまでバラバラに発展してきたAIの記憶技術には、実は共通する根本原理があったという理論を示しています。
MIRASを具現化したTitans
このMIRASの設計理論を具体化したのが、今回MIRASとともに発表されたTitansです。Titansの驚異的な精度は、長文処理能力を測る評価テスト「BABILong」の結果で証明されています。
MIRASを実装したTitansが登場すれば、製造現場の図面や日報は自動整理され、必要な情報をすぐ取り出せるようになるでしょう。AIの進化は速く、その未来は目前です。
製造業・建設業向け生成AI無料オンラインセミナーは、現場レベルのAI活用術、最新の成功事例、さらには人材育成の具体策まで幅広く学べるおすすめのカリキュラムです。
Titansの「BABILong」の結果については、以下の記事をご参照ください。GPT-4やRMT-FTを圧倒した実力を、グラフで分かりやすくお伝えしています。
MIRASが登場した背景
Google Researchは、AIの構造的な限界を背景にMIRASを考案しました。
AIのシーケンスモデルが抱えていた弱点
AIの中でも、テキスト・音声・時系列データなど、順序に意味がある情報を扱うシーケンスモデルには、それぞれ明確な弱点が存在していました。
トランスフォーマー(ChatGPTやGemini)
現在主流のトランスフォーマーは、アテンション(注意機構)だけで高性能なモデルが作れ、かつ同時に計算(並行処理)できるのが特長です。一方で、情報量が増えるほど記憶しきれなくなり、動作も重くなるという課題がありました。
線形RNN(MambaやRWKVなど)
この課題を解決するために生まれたのが線形RNNで、これは情報を圧縮しながら次のステップへ受け渡すため軽快に動作します。しかし、情報を圧縮するがゆえ、細かい情報を長く保持するのは得意ではありません。
解決のヒントは「人間の記憶」
この解決策として注目されたのが、人間の脳が持つ「アテンショナルバイアス(注意の偏り)」です。アテンショナルバイアスでは、感情や重要度を元にインプットした情報を無意識に選別します。例えば、
- 入社式当日の緊張感は強い記憶に残る
- 興味のない会話は数時間で忘れる
こういった状況がアテンショナルバイアスです。人間では当たり前の脳の働きですが、AIの場合、情報は同一レベルで受け止め、新しい情報が入ってくると過去の情報は消えてしまいます。
MIRASはアテンショナルバイアスを応用
MIRASはこの仕組みをAIに取り込み、すべてのモデルを連想記憶(関連付けて覚える仕組み)として捉え直しました。
具体的には、情報を「キー(きっかけ)」と「値(中身)」で整理し、アテンショナルバイアスを基準に情報を選別する仕組みです。このMIRASの仕組みを製造現場の例で見ると、
- 設備が「温度上昇」というキーを検知する
- MIRASは大量のデータの値をリサーチする
- 温度上昇と関係が強い情報を優先して取り出す
といった感じです。さらに、忘れることを「記憶を整理して保つための調整(保持正則化)」として扱う発想も導入しました。
こうしてMIRASは、「重要な情報を記憶し、不要な情報を自然に手放す」という、人間に近い記憶構造を持つフレームワークとして誕生したのです。
トランスフォーマーについては、以下の記事をご参照ください。トランスフォーマーを基盤とした、生成AIの仕組みもわかりやすくお伝えしています。
MIRASのフレームワーク
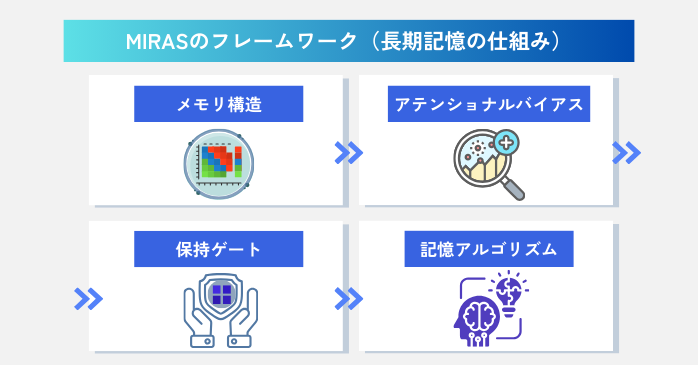
MIRASでは、AIが長期記憶を形作るためには、以下の4つの要素が順番に連動することで機能すると提唱しています。
①情報を蓄える場所を用意(メモリ構造)
まず最初に決めるのは、入力した情報を保存する形式です。従来の選択肢は、単純なベクトルや行列でしたが、MIRASはこれに加えて以下のような選択肢を提示します。
- 線形関数:入力値と出力値が比例する関数
- 多層パーセプトロン(MLP):ニューラルネットワークの基本
- 深層ニューラルネットワーク:多層化したニューラルネットワーク
MIRASを実装したTitansは、上記の深層ニューラルネットワークを選択し、データ間の関係性を含んだ情報を保存します。例えば、「モーターの振動が大きい」という情報は、
- 振動が大きい → ベアリング摩耗の可能性(因果関係)
- 停止直後の振動 → 冷却ファンの惰性で正常(文脈依存)
といったように、単独で覚えず「同じ振動でも状況によって意味が変わる」という条件付きの知識として記憶します。
②重要度を選別(アテンショナルバイアス)
次に決めるのは、入ってきた情報から「何を記憶すべきか」を判断する基準です。既存モデルの多くは、以下2つのどちらかしか使っていませんでした。
- ドット積類似度(トランスフォーマーや線形RNN)
- L2回帰(一部のメモリネットワーク)
MIRASは、これらを「アテンショナルバイアス」として統一的に説明し、すべて同じ枠組みで理解できることを示しました。例えば、
- 重要な約束の日時は優先的に記憶
- 挨拶や相槌は軽く流す
というように、情報の重要度に応じた選別を行います。これにより、すべてを同じ重みで扱うことで本当に大切な内容が埋もれてしまう問題を解決しています。
③重要な記憶を守りながら調整(保持ゲート)
MIRASでは、次のステップとして「過去の記憶をどれだけ保持するか」を決定します。
ここで、従来のAIが採用してきた「忘却ゲート」を、MIRASでは「保持ゲート」として再定義しました。なぜなら、忘却ゲートといっても実際には記憶を消すのではなく、「どの記憶を残すか」を調整しているだけだからです。
MIRASのフレームワークでは、この保持ゲートで新旧の記憶のバランスを取ります。例えば会話の中では、
- 「上司の名前は田中さん」→ 長期保持
- 「今日の天気は晴れ」→ 徐々に薄れる
といったように、情報の性質に応じて保持期間を変えることで、大切な記憶を守りながら新しい知識を受け入れる仕組みを実現しています。
④情報の書き込み・更新(記憶アルゴリズム)
最後に、選別された情報を「どうやって記憶として書き込むか」を決めます(更新ルール)。MIRASでは、この更新ルールとして、以下の複数の方法を提示しています。
- 勾配降下法:基本的な最適化
- モメンタム:勢いをつけて速く収束
- ミラー降下法:制約のある問題に強い
- 非パラメトリック:ルールを固定せず柔軟に更新
この仕組みにより、AIは推論中でも学習を継続できます。例えば会話中に、
- 「田中さんはものづくりが趣味」という新情報を学習
- 「では、おすすめの3Dプリンターを紹介します」と活用
というように、その場で経験を知識に変換し、リアルタイムで自己更新していきます。従来のAIのように「学習フェーズ」と「推論フェーズ」を分ける必要がないのです。
セミナーで最新生成AI活用・導入の具体策を学ぼう!
MIRASの仕組みは画期的ですが、専門用語が多く「結局、自社の現場でどう役立つの?」と感じた方もいるかと思います。
そんな方は、製造業・建設業向け 生成AI無料オンラインセミナーで製造業のAI活用情報や活用事例、導入のコツまで、実践的に学びましょう。短時間で行うライブ配信型セミナーなので、鮮度の高い最新情報が効率的に身に付きます。
セミナー名 製造業・建設業向けDX無料オンラインセミナー 日時 アーカイブ配信中 価格 無料 開催場所 Zoomウェビナー(オンライン)
MIRASとTitansの関係
 MIRASとTitansは、理論とモデルという関係にあります。具体的には、
MIRASとTitansは、理論とモデルという関係にあります。具体的には、
- MIRAS:設計図(設計のフレームワーク)
- Titans:MIRASの設計図を元にした構造(具体的実装)
といった位置づけになります。ただし、この関係はMIRASとTitansの二者だけで完結するものではありません。
MIRASは多様なモデルを構築できる
MIRASの論文では「Titansが最良」と主張しているわけではなく、構成要素の組み合わせで多様なモデルを構築できるフレームワークと定義しています。例えば、
- メモリ構造:ベクトル、行列、MLP、深層ネットワーク
- アテンショナルバイアス:ドット積、L2、その他の新しいバイアス
- 記憶アルゴリズム:勾配降下、ミラー降下、モメンタム
といった設計要素を、タスクや制約に応じて柔軟に組み合わせられます。
TitansはMIRASの4要素をどう実装したか?
MIRASが定義する4つの設計選択に対して、Titansは以下のように実装しました。
| MIRASの4要素 | Titansの実装 | 概要 |
| メモリ構造 | k層 MLP | 深い構造で記憶容量を拡張 |
| アテンショナルバイアス | L2(回帰型) | 誤差を最小化して精密に記憶 |
| 保持ゲート | L2 正則化 | 新旧の記憶バランスを安定化 |
| 記憶アルゴリズム | 勾配降下+モメンタム | 推論中でも学習を続行 |
上記で特に注目したいのは、メモリ構造として採用されている「k層 MLP」です。これは、従来のトランスフォーマーのような行列メモリではなく、多層のMLPをそのままメモリとして用い、その深い構造により長期記憶を実現しています。
MIRASから生まれた3つの新モデル
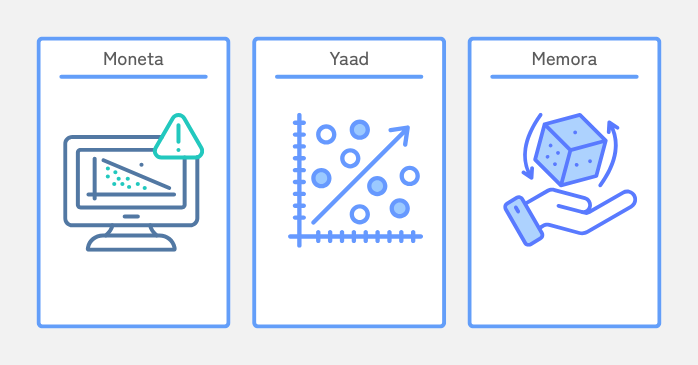
MIRASの論文では、Titansに続く3つのモデルも紹介されています。
| モデル名 | 内容 | 主な特徴 |
| Moneta(モネタ) | Lp/Lq 目的関数 | 異常値やノイズに強く、重要情報を正確に更新 |
| Yaad(ヤアド) | Huber loss | データのバラつきに強く、安定した記憶を維持 |
| Memora(メモラ) | Softmax&KLダイバージェンス | 記憶を確率として捉え、複雑な文脈にも対応 |
これらのモデルは、言語理解・推論、長期記憶が必要なタスクでトランスフォーマーや線形RNNを上回るスコアを記録しています。
3つのモデルはMIRASの目的の実証例
MIRASの目的は、より高性能なモデルを生み出す汎用的な設計フレームワークを提供することです。実際、MIRASから派生した3つのモデルについて論文では次のように述べられています。
The results illustrates the superior performance of these variants,
outperforming state-of-the-art sequence models.
(これらのモデルは、最先端のシーケンスモデルを上回る優れた性能を示している。)
このことから、MIRASは「次世代モデルを設計するための基盤」であり、TitansはMIRASが生み出すモデルの一例にすぎないことがわかります。
Googleの長期記憶を実現するAIといえばTitansに注目が集まり、MIRASはその一部のように見られがちです。しかし実際にはその逆で、MIRASという大きな枠組みの中にTitansが位置づけられているのです。
MIRASについてまとめ
MIRASは「モデル設計の共通ルール」を定義したフレームワークで、その原理を分かりやすく示したのがTitansです。
Titansが示したGPT-4を凌ぐ長期記憶性能を背景に、今後はMIRASを基盤としてTitans以外の新モデルも次々と生まれていく未来が見込まれます。